


本文深入解读 DeepSeek-R1 及类强推理模型的开发,分析其在强推理慢思考范式下的创新,详细剖析技术细节,并探讨其社会及经济效益,对比不同技术路线,展望未来发展方向。

资料简介
该资料深入解读了 DeepSeek-R1 及类强推理模型的开发。
文章首先分析了 DeepSeek-R1 在强推理慢思考范式下的创新,其通过纯强化学习驱动,展现出强大的推理能力和长文本思考能力。
接着详细剖析了 DeepSeek-R1 Zero 及 R1 的技术细节,包括基于规则的奖励机制、推理为中心的强化学习、组相对策略优化(GRPO)等技术。
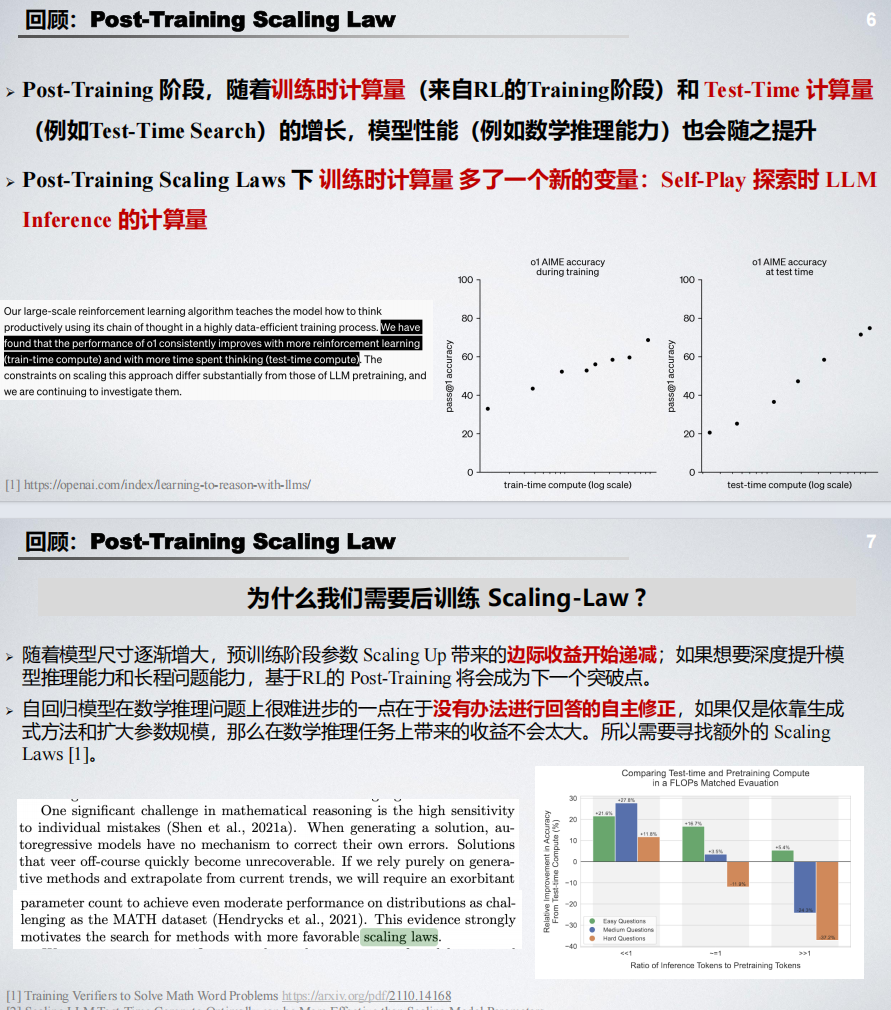
文章还探讨了 DeepSeek-R1 背后的技术启示,如推理能力的涌现、长度泛化等,并讨论了其社会及经济效益,指出其在开源社区与闭源大模型竞争中的关键作用。
此外,文章对比了 STaR-based 方法与 RL-based 方法,分析了蒸馏与强化学习驱动的技术路线,并探讨了 PRM、MCTS 的作用以及从文本模态到多模态的拓展。
最后,文章对未来发展方向进行了展望,包括模态穿透赋能推理边界拓展、合成数据及 Test-Time Scaling、强推理下的安全等。
部分内容展示



免责声明: 素材来自网络,费用为整理费用,如有侵权请联系删除。
